
Ein persönlicher Erfahrungsbericht von OpenManus auf einer runpod.io-Instanz (Teil 2)
In diesem Beitrag beschreibe ich meine Erfahrungen mit OpenManus. Er ist eine Fortsetzung von Teil 1 und knüpft dort nahtlos an.
Nachdem ich beim letzten Mal nicht gut nachvollziehen konnte, was das LLM im Browser unternimmt, möchte ich den Test heute auf einem PC mit grafischer Benutzeroberfläche fortführen. Dazu bediene ich mich eines Desktop-Computers mit Ubuntu 24. Da der Computer nicht genug Ressourcen hat, LLMs lokal auszuführen, lasse ich die Ollama-Instanz weiter bei runpod.io laufen. Weiterhin binde ich im Laufe des Tests weitere Modelle über deren Public-APIs an.
Zuerst konfiguriere ich meinen Runpod-Container so um, dass er Anfragen auf Port 11434 annimmt. Diese werden dann intern auf Port 22025 weitergeleitet. Dies gilt es beim Starten von Ollama zu beachten.
Die Schritte zur Vorbereitung des Containers gleichen ansonsten denen, die in der letzten Woche gezeigt wurden.
Folgende Befehle werden zum Start von Ollama ausgeführt:
OLLAMA_HOST=0.0.0.0:22062 ollama serve &
OLLAMA_HOST=0.0.0.0:22062 ollama run qwq
/bye
OLLAMA_HOST=0.0.0.0:22062 ollama run minicpm-v
/bye!!! An dieser Stelle sei gesagt, dass Ollama keine Authentifikation mitbringt. Das hier gehostete Modell ist nun öffentlich im Internet. Daher empfiehlt sich dieses hier gezeigte Setup wenn überhaupt nur für ganz kurze und kleine Tests. Möchte man länger damit arbeiten, empfehle ich einen SSH-Tunnel. Dass hier die IP-Adressen gezeigt werden, ist kein Problem, da diese dynamisch von Runpod vergeben werden !!!
Nachdem der Server nun läuft, passe ich die Konfiguration an:
[llm] #OLLAMA:
api_type = 'ollama'
model = "qwq" # The LLM model to use
base_url = "http://194.68.245.198:11434/v1" # API endpoint URL
api_key = "ollama" # Your API key
max_tokens = 4096 # Maximum number of tokens in the response
temperature = 0.0
# api_type = 'ollama'
model = "minicpm-v" # The vision model to use
base_url = "http://194.68.245.198:11434/v1" # API endpoint URL for vision model
api_key = "ollama" # Your API key for vision model
max_tokens = 4096 # Maximum number of tokens in the response
temperature = 0.0Mit diesem Setup starte ich den ersten Test. Als Prompt benutze ich: "Please order me a Geforce RTX 5090. I am living in Germany."
Der Agent legt los und im Gegensatz zur Headless-Variante öffnet sich automatisch ein Browserfenster. Der Agent steuert die erste Händlerseite an.
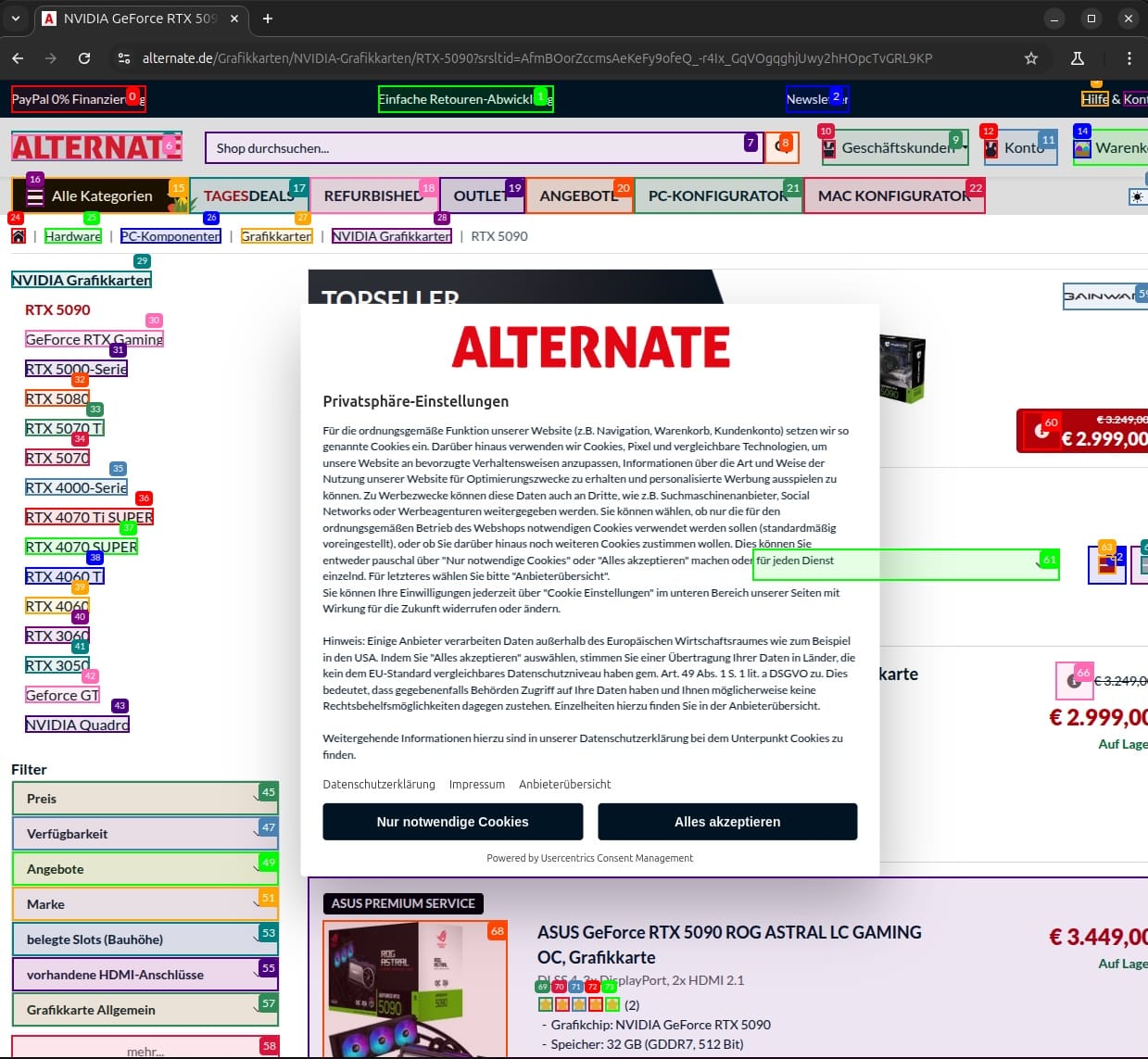
Das erscheinende Cookiebanner ist allerdings eine Hürde für den Agenten. Hier muss ich manuell nachhelfen. Danach geht es weiter. Nun muss das im Browser gezeigte vom LLM interpretiert werden. Genau dabei hat das Gespann aus QWQ und MiniCPM-V Probleme. In der Konsole erscheint 'No content was extracted from the page'. Danach scrollt das Modell in jedem Schritt noch etwas durch die Seite. Mehr passiert nicht.
Ich bin sehr gespannt, was größere undistilled-Sprachmodelle können. Daher konfiguriere ich OpenManus kurzerhand so um, dass es sowohl als LLM als auch als Modell für die Bilderkennung GPT4o benutzt.
[llm]
model = "gpt-4o"
base_url = "https://api.openai.com/v1"
api_key = "sk-proj-***" # Replace with your actual API key
max_tokens = 4096
temperature = 0.0
[llm.vision]
model = "gpt-4o"
base_url = "https://api.openai.com/v1"
api_key = "sk-proj-***"Dieses Modell steuert statt Alternate den Mitbewerber Caseking an. So weit so gut, jedoch scheitert es direkt an einer Cloudflare-Boterkennung:
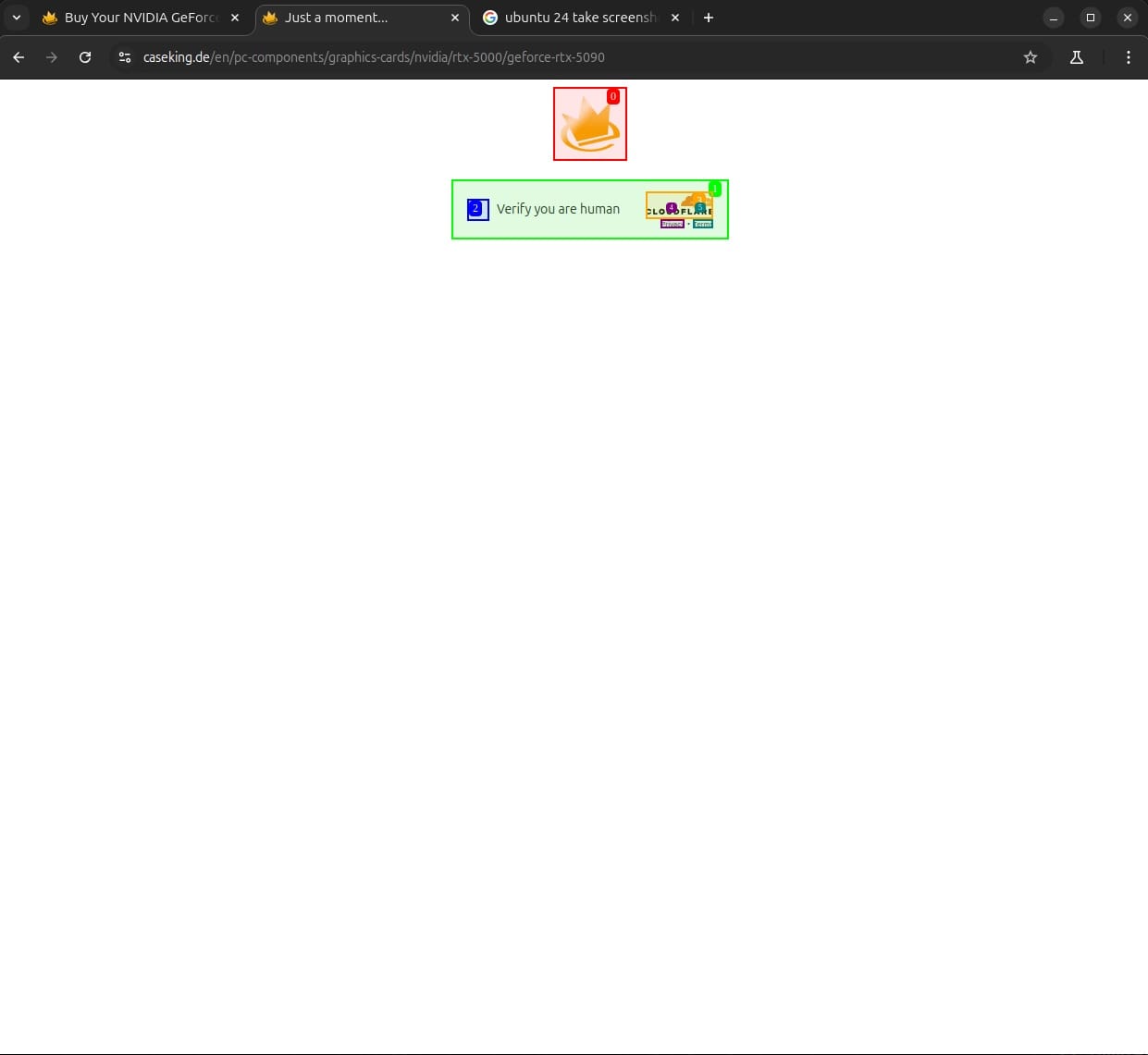
Hier hilft manuelles Eingreifen leider nicht. Trotz Anklickens des Captchas lässt sich die Webseite im automatisierten Browser nicht öffnen. Daher ändere ich den Prompt und fordere den Agenten dazu auf ebenfalls Alternate anzusteuern. Nachdem die Seite durch manuelle Hilfe beim Cookie-Banner geöffnet ist, schafft es GPT4o Inhalt von der Seite zu extrahieren.
Nachdem es anfänglich gut aussieht, beginnt der Bot eine Irrfahrt über die Webseite und landet über einen Umweg über das Retourencenter schließlich bei der Newsletteranmeldung. Danach verlässt der Bot sogar die Webseite und sucht bei Reddit weiter. Am Ende merkt er selbst, dass dies zu nichts führt und macht zum Schluss einen Vorschlag, wie man selbst weitermachen könnte:

Motiviert von einem Teilerfolg probiere ich Claude 3.7 aus. Leider wird aus der Euphorie schnell Ernüchterung. Claude 3.7 ruft ebenso Alternate im Browser auf und findet die Übersicht über die RTX 5090-Grafikkarten, scheitert dann aber bei der Auswertung:
2025-04-11 17:04:26.331 | ERROR | app.llm:ask_tool:763 - OpenAI API error: Error code: 400 - {'error': {'code': 'invalid_request_error', 'message': 'At least one non-system, non-developer message is required.', 'type': 'invalid_request_error', 'param': None}}Eine Kombination aus GPT4o als LLM und Claude 3.7 als Vision-LLM liefert bessere Ergebnisse, kommt jedoch nicht an den Einsatz von GPT4o als LLM und Vision-LLM heran.
Insgesamt ist dies ein eher enttäuschender Test. Erwartet hatte ich, dass sich die Modelle für eine verfügbare Grafikkarte entscheiden, diese in den Warenkorb legen und beim Starten des Bezahlvorgangs abbrechen oder mich um Hilfe bitten. Ich kann mir gut vorstellen, dass diese Zielverfehlung daran liegt, dass LLMs am besten englisch können. Deutsche Webseiten sind dabei eine größere Herausforderung. Weiterhin gibt es den Cookiebanner nur in der EU. Woran es aber letztendlich wirklich liegt, dass die Testergebnisse so schlecht sind, weiß ich nicht. Ich bleibe am Thema dran und werde auch über andere Agenten berichten.
